YOLO v1 개요
-
YOLO v1 모델은 기존의 2-stage detector 방식(R-CNN 계열 등)과 달리, 단일 신경망을 사용하여 입력 이미지에서 객체 위치(localization)와 분류(classification)를 동시에 수행하는 1-stage detector 접근 방식을 제안함.
-
당시 정확도(mAP)는 2-stage detector인 Faster R-CNN 보다 부족하였지만, 이미지 전체를 한 번만 보고 예측하므로(You Only Look Once), 매우 빠른 실시간 객체 탐지 속도를 달성하여 딥러닝 기반 실시간 객체 탐지 모델의 표준을 제시함.
-
Paper: You Only Look Once: Unified, Real-Time Object Detection (CVPR 2016)
Key-Points

- localization과 classification을 하나의 문제로 정의하여 network가 동시에 두 task를 수행하도록, 이미지를 지정한 grid로 나누고, 각 grid cell이 한번에 bounding box와 class 정보라는 2가지 정답을 도출하도록 함.
- 또한 각 grid cell에서 얻은 정보를 feature map이 잘 encode할 수 있도록 독자적인 Convolutional Network인 DarkNet을 도입함.
- 이를 통해 얻은 feature map을 활용하여 자체적으로 정의한 regression loss를 통해 전체 모델을 학습시킴.
1-stage detector
- YOLO v1은 별도의 region proposals를 사용하지 않고 전체 이미지를 입력에 사용하며, 이를 통해 selective search를 사용한 Fast R-CNN에 비해 background error(배경 이미지를 배경이라고 정확하게 인식)를 두 배 이상 줄였다.
- 또한, 전체 이미지에 대하여 학습을 하기 때문에 다른 도메인에서도 좋은 성능을 보인다. (일반화)
Grid Cell

- 입력 이미지를 (S x S) 크기의 grid로 분할하고, groud truth의 객체 중심이 포함된 grid cell은 그 객체를 학습할 수 있는 cell로 할당(objectness = true) 된다. (중심 셀이 아닌 나머지 셀은 GT가 없기 때문에 bbox loss를 계산하지 않는다)
- 이때, 한 grid cell 안에 객체 중심이 2개 이상 들어오는 경우, GT 중 가장 큰 객체를 선택하거나 먼저 할당된 객체를 유지하는 방법으로 grid cell과 객체는 1:1 매칭되도록 한다. (결과적으로 작은 중첩된 객체는 모두 검출하기 어려움)
- CNN의 마지막 feature map의 공간 차원이 곧 그리드 정보를 대표함 : CNN의 구조적 특성으로 인해 이 7×7 feature map의 각 cell은 원본 이미지의 특정 공간 영역(Receptive Field) 을 대표함.
Prediction of Grid Cell
- YOLO v1에서 각 그리드 셀은 다음을 예측한다.
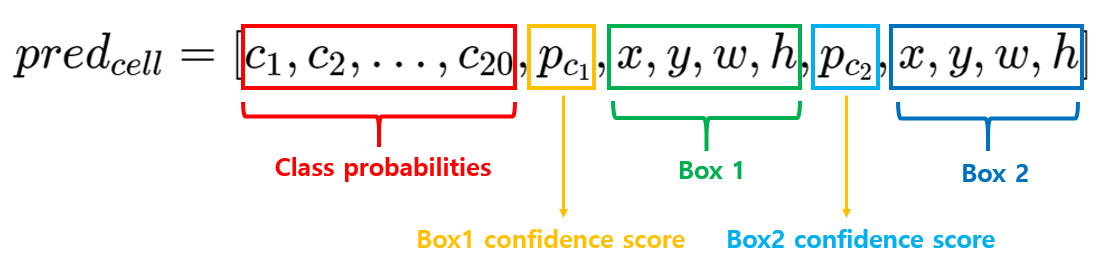
- B개의 bounding box 정보 = {x, y, w, h, confidence score}
- C개의 클래스 확률
confidence score
- 각 grid cell은 B개의 bounding box에 대한 각 confidence score를 예측함.
- confidence score는 얼마나 정확하게 GT box를 예측했는지를 나타내는 수치로, 아래 두 항의 곱으로 계산됨.
-
: 현재 셀이 특정 객체(GT)에 할당되었는지 (0 또는 1)
-
: 현재 box와 GT의 겹치는 정도(IoU)
-
따라서, grid cell 내에 객체가 존재하지 않는다면 confidence score는 0이 되며, 객체가 존재한다면 IoU 값과 같아진다.
bounding box
- 각 바운딩 박스는 {x, y, w, h, confidence socre} 의 5개의 예측값을 가진다.
- (x, y) : box의 중심. 상대 좌표로 표현.
- (w, h) : box의 가로, 세로 크기. 상대 좌표로 표현.
- 학습 시, grid cell에서 예측된 B개의 bounding box 중 confidence score가 가장 높은 1개의 box만 사용한다.
conditional class probabilities
- 각 gird cell은 C개의 조건부 클래스 확률인 를 예측함.
- 해당 grid cell에 객체가 존재한다고 가정했을 때, 그 객체가 클래스 일 확률을 의미하며, 객체가 할당되지 않은 cell에 대한 값은 학습에 사용되지 않는다.
Total Prediction
- 최종적으로 SxS 크기의 grid에 대해, 각 grid cell 마다 B개의 bounding box 정보 각 5개와 클래스 개수 C개의 확률값으로 구성되어 각 grid cell에 대해 (Bx5+C)개의 예측값으로 구성된다.
- YOLO v1에서는 S=7(7x7 grid), B=2(2개의 예측 box), C=20(클래스 개수)로 구성되어, 최종적으로 CNN 네트워크를 거쳐 7x7x30 형태의 tensor가 출력되도록 구성함.
YOLO v1 구조 및 학습
DarkNet
-
YOLO v1 모델은 최종 예측값의 크기인 7x7x30에 맞는 feature map을 생성하기 위해 GoogLeNet에 영감을 받은 DarkNet이라는 CNN 구조를 설계함.

-
네트워크는 24개의 convolutional layer와 2개의 fully connected layer로 구성되며, GooLeNet에서 사용한 inception 컨셉 대신 1x1 convolution layer를 사용함
학습 전략 및 방법
- 무작위 초기화 상태에서 detection을 바로 학습하면 수렴이 매우 불안정하며, 이를 해결하기 위해 YOLO v1은 2단계 학습 전략을 사용함.
- ImageNet Classification 데이터셋으로 사전학습(pretraining) 후 Detection task로 fine-tuning.
- 1단계 : 초기 20개의 convolution layer는 ImageNet 데이터셋을 이용해 pretrain을 진행함. 이때 classification 전용 네트워크 형태로 일부를 수정하기 위해 20개 Conv layer 뒤에 Average Pooling과 Fully Connected layer를 추가하여 학습.
- 1단계 사전학습에서 입력 이미지 해상도는 224x224로 하고, 출력은 1000개의 ImageNet class 확률이 됨.
- 2단계 : 1단계에서 사용한 후반 분류용 layer를 제거하고 4개의 Conv layer 와 2개의 Fully Connected layer를 추가하여 전체 네트워크를 fine-tuning 함. 출력은 7×7×30 (VOC 30개 class 기준).
- 2단계 학습 단계에서는 입력 이미지 해상도를 224x224로 시작하여 448x448로 증가시키는 전략을 사용하여, localization 정밀도를 높인다.
Loss Function
- YOLO v1은 MSE 기반 손실 함수를 사용하며, 크게 세 가지 요소로 구성된다.
